
In 2011 I wrote a post here on Moz. The title was “Wake Up SEOs, the New Google is Here.”
In that post I presented some concepts that, in my personal opinion, we SEOs needed to pay attention to in order to follow the evolution of Google.
Sure, I also presented a theory which ultimately proved incorrect; I was much too confident about things like rel=”author”, rel=”publisher”, and the potential decline of the Link Graph influence.
However, the premises of that theory were substantially correct, and they remain correct five years later:
- Technical SEO is foundational to the SEO practice;
- The user is king, which means that Google will focus more and more on delivering the best user search experience — hence, SEO must evolve from “Search Engine Optimization” into “Search Experience Optimization”;
- That web performance optimization (SiteSpeed), 10X content, and semantics would have played a big role in SEO.
Many things have changed in our industry in the past 5 years. The time has come to pause, take a few minutes, and assess what Google is and where it’s headed.
I’ll explain how I “study” Google and what I strongly believe we, the SEOs, should pay attention to if we want not only to survive, but to anticipate Google’s end game, readying ourselves for the future.
Obviously, consider that, while I believe it’s backed up by data, facts, and proof, this is my opinion. As such, I kindly ask you not to take what I write for granted, but rather as an incentive for your own investigations and experiments.
Exploring the expanded universe of Google

Credit: Robson Ribeiro
SEO is a kingdom of uncertainty.
However, one constant never changes: almost every SEO dreams of being a Jedi at least once in her life.
I, too, fantasize about using the Force… Gianlu Ka Fiore Lli, Master Jedi.
Honestly, though, I think I’m more like Mon Mothma.
Like her, I am a strategist by nature. I love to investigate, to see connections where nobody else seems to see them, and to dig deeper into finding answers to complex questions, then design plans based on my investigations.
This way of being means that, when I look at the mysterious wormhole that is Google, I examine many sources:
- The official Google blogs;
- The “Office Hours” hangouts;
- The sometimes contradictory declarations Googlers make on social media (when they don’t share an infinite loop of GIFs);
- The Google Patents and the ones filed by people now working for Google;
- The news (and stories) about the companies Google acquires;
- The biographies of the people Google employs in key areas;
- The “Google Fandom” (aka what we write about it);
- Rumors and propaganda.
Now, when examining all these sources, it’s easy to create amazing conspiranoiac (conspiracy + paranoia) theories. And I confess: I helped create, believed, and defended some of them, such as AuthorRank.
In my opinion, though, this methodology for finding answers about Google is the best one for understanding the future of our beloved industry of search.
If we don’t dig into the “Expanded Universe of Google,” what we have is a timeline composed only by updates (Panda 1.N, Penguin 1.N, Pigeon…), which is totally useless in the long term:
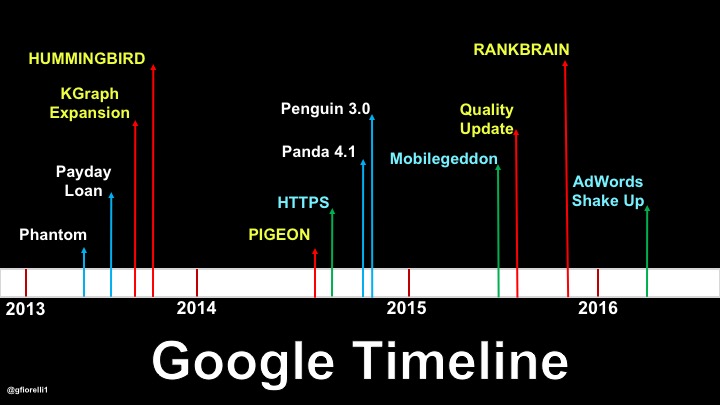
Click to open a bigger version in a new tab
Instead, if we create a timeline with all the events related to Google Search (which we can discover simply by being well-informed), we begin to see where Google’s heading:
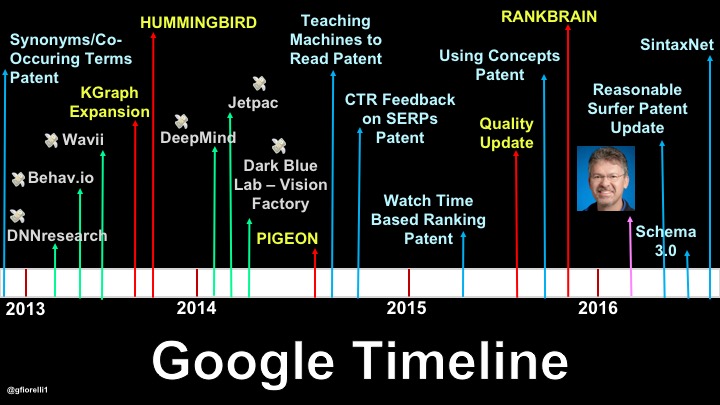
Click to open a bigger version in a new tab
The timeline above confirms what Google itself openly declared:
“Machine Learning is a core, transformative way by which we’re rethinking how we’re doing everything.”
– (Sundar Pichai)
Google is becoming a “Machine Learning-First Company,” as defined by Steven Levy in this post.
Machine learning is becoming so essential in the evolution of Google and search, perhaps we should go beyond listening only to official Google spokespeople like Gary Illyes or John Mueller (nothing personal, just to be clear… for instance, read this enlightening interview of Gary Illyes by Woj Kwasi). Maybe we should start paying more attention to what people like Christine Robson, Greg Corrado, Jeff Dean, and the staff of Google Brain write and say.
The second timeline tells us that starting in 2013 Google started investing money, intellectual efforts, and energy on a sustained scale in:
- Machine learning;
- Semantics;
- Context understanding;
- User behavior (or “Signals/Semiotics,” as I like to call it).
2013: The year when everything changed
Google rolled out Hummingbird only three years ago, but it’s not just a saying: that feels like decades ago.
Let’s quickly rehash: what’s Hummingbird?

Hummingbird is the Google algorithm as a whole. It’s composed of four phases:
- Crawling, which collects information on the web;
- Parsing, which identifies the type of information collected, sorts it, and forwards it to a suitable recipient;
- Indexing, which identifies and associates resources in relation to a word and/or a phrase;
- Search, which…
- Understands the queries of the users;
- Retrieves information related to the queries;
- Filters and clusters the information retrieved;
- Ranks the resources; and
- Paints the search result page and so answers the queries.
This last phase, Search, is where we can find the “200+ ranking factors” (RankBrain included) and filters like Panda or anti-spam algorithms like Penguin.
Remember that there are as many search phases as vertical indices exist (documents, images, news, video, apps, books, maps…).
We SEOs tend to fixate almost exclusively on the Search phase, forgetting that Hummingbird is more than that.
This approach to Google is myopic and does not withstand a very simple logical square exercise.
- If Google is able to correctly crawl a website (Crawling);
- to understand its meaning (Parsing and Indexing);
- and, finally, if the site itself responds positively to the many ranking factors (Search);
- then that website will be able to earn the organic visibility it aims to reach.
If even one of the three elements of the logical square is missing, organic visibility is missing; think about non-optimized AngularJS websites, and you’ll understand the logic.

The website on the left in a non-JS enabled browser. On the right, JS enabled reveals all of the content. Credit: Builtvisible.com
How can we be SEO Jedi if we only see one facet of the Force?
Parsing and indexing: often forgotten
Over the past 18 months, we’ve a sort of technical SEO Renaissance, as defined by Mike King in this fundamental deck and despite attempts to classify technical SEOs as makeup artists.
On the contrary, we’re still struggling to fully understand the importance of the Parsing and Indexing phases.
Of course, we can justify that by claiming that parsing is the most complex of the four phases. Google agrees, as it openly declared when announcing SintaxNet.

However, if we don’t optimize for parsing, then we’re not going to fully benefit from organic search, especially in the months and years to come.
How to optimize for parsing and indexing
As a premise to parsing and indexing optimization, we must remember an oft-forgotten aspect of search, which Hummingbird highlighted and enhanced: entity search.
If you remember what Amit Singhal said when he announced Hummingbird, he declared that it had “something of Knowledge Graph.”
That part was — and I’m simplifying here for clarity’s sake — entity search, which is based over two kinds of entities:
- Named entities are what the Knowledge Graph is about, such as persons, landmarks, brands, historic movements, and abstract concepts like “love” or “desire”;
- Search entities are “things” related to the act of searching. Google uses them to determine the answer for a query, especially in a personalized context. They include:
- Query;
- Documents and domain answering to the query;
- Search session;
- Anchor text of links (internal and external);
- Time when the query is executed;
- Advertisements responding to a query.
Why does entity search matter?
It matters because entity search is the reason Google better understands the personal and almost unique context of a query.
Moreover, thanks to entity search, Google better understands the meaning of the documents it parses. This means it’s able to index them better and, finally, to achieve its main purpose: serving the best answers to the users’ queries.
This is why semantics is important: semantic search is optimizing for meaning.

Credit: Starwars.com
It’s not a ranking factor, it’s not needed to improve crawling, but it is fundamental for Parsing and Indexing, the big forgotten-by-SEOs algorithm phases.
Semantics and SEO
First of all, we must consider that there are different kinds of semantics and that, sometimes, people tend to get them confused.
- Logical semantics, which is about the relations between concepts/linguistic elements (e.g.: reference, presupposition, implication, et al)
- Lexical semantics, which is about the meaning of words and their relation.
Logical semantics
Structured data is the big guy right now in logical semantics, and Google (both directly and indirectly) is investing a lot in it.
A couple of months ago, when the mainstream marketing gurusphere was discussing the 50 shades of the new Instagram logo or the average SEO was (justifiably) shaking his fists against the green “ads” button in the SERPs, Google released the new version of Schema.org.
This new version, as Aaron Bradley finely commented here, improves the ability to disambiguate between entities and/or better explain their meaning.
For instance, now:
At the same time, we shouldn’t forget to always use the most important property of all: “SameAs”, one of few properties that’s present in every Schema.org type.

Finally, as Mike Arnesen recently explained quite well here on the Moz blog, take advantage of the semantic HTML attributes ItemRef and ItemID.
How do we implement Schema.org in 2016?
It is clear that Google is pushing JSON-LD as the preferred method for implementing Schema.org
The best way to implement JSON-LD Schema.org is to use the Knowledge Graph Search API, which uses the standard Schema.org types and is compliant with JSON-LD specifications.
As an alternative, you can use the recently rolled out JSON-LD Schema Generator for SEO tool by Hall Analysis.
To solve a common complaint about JSON-LD (its volume and how it may affect the performance of a site), we can:
- Use Tag Manager in order to fire Schema.org when needed;
- Use PreRender in order to let the browser begin uploading the pages your users may visit after the one they’re currently on, anticipating the upload of the JSON-LD elements of those pages.
The importance Google gives to Schema.org and structured data is confirmed by the new and radically improved version of the Structured Data Testing Tool, which is now more actionable for identifying mistakes and test solutions thanks to its JSON-LD (again!) and Schema.org contextual autocomplete suggestions.
Semantics is more than structured data #FTW!
One mistake I foresee is thinking that semantic search is only about structured data.
It’s the same kind of mistake people do in international SEO, when reducing it to hreflang alone.
The reality is that semantics is present from the very foundations of a website, found in:
- Its code, specifically HTML;
- Its architecture.
HTML
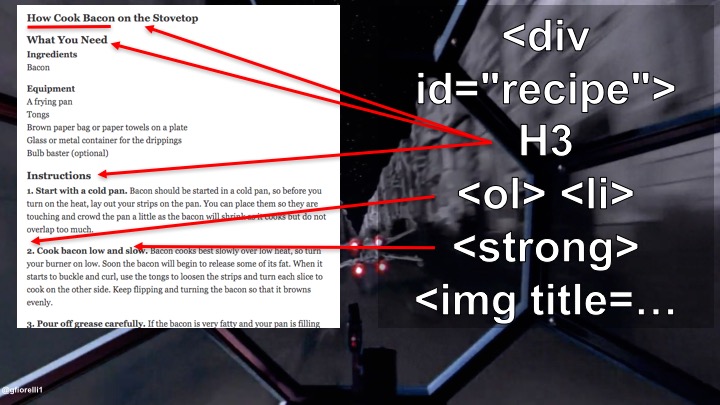
Click to open a bigger version in a new tab
Since its beginnings, HTML included semantic markup (e.g.: title, H1, H2…).
Its latest version, HTML5, added new semantic elements, the purpose of which is to semantically organize the structure of a web document and, as W3C says, to allow “data to be shared and reused across applications, enterprises, and communities.”
A clear example of how Google is using the semantic elements of HTML are its Featured Snippets or answer boxes.
As declared by Google itself (“We do not use structured data for creating Featured Snippets”) and explained well by Dr. Pete, Richard Baxter, and very recently Simon Penson, the documents that tend to be used for answer boxes usually display these three factors:
- They already rank on the first page for the query pulling out the answer box;
- They positively answer using basic on-page factors;
- They have a clean — or almost clean — HTML code
The conclusion, then, is that semantic search starts in the code and that we should pay more attention to those “boring,” time-consuming, not-a-priority W3C error reports.
Architecture
The semiotician in me (I studied semiotics and the philosophy of language in university with the likes of Umberto Eco) cannot help but not consider information architecture itself as semantics.
Let me explain.

Open http://www.starwars.com/ in a tab of your browser to follow along below
Everything starts with the right ontology
Ontology is a set of concepts and categories in a subject area (or domain) that shows their properties and the relations between them.
If we take the Starwars.com site as example, we can see in the main menu the concepts in the Star Wars subject area:
- News/Blog;
- Video;
- Events;
- Films;
- TV Shows;
- Games/Apps;
- Community;
- Databank (the Star Wars Encyclopedia).
Ontology leads to taxonomy (because everything can be classified)
If we look at Starwars.com, we see how every concept included in the Star Wars domain has its own taxonomy.
For instance, the Databank presents several categories, like:
- Characters;
- Creatures;
- Locations;
- Vehicles;
- Et cetera, et cetera.
Ontology and taxonomy, then, lead to context
If we think of Tatooine, we tend to think about the planet where Luke Skywalker lived his youth.
However, if we visit a website about deep space exploration, Tatooine would be one of the many exoplanets that astronomers have discovered in the past few years.
As you can see, ontology (Star Wars vs celestial bodies) and taxonomies (Star Wars planets vs exoplanets) determine context and help disambiguate between similar entities.
Ontology, taxonomy, and context lead to meaning
The better we define the ontology of our website, structure its taxonomy, and offer better context to its elements, the better we explain the meaning of our website — both to our users and to Google.
Starwars.com, again, is very good at doing this.
For instance, if we examine how it structures a page like the one on TIE fighters, we see that every possible kind of content is used to help explain what a TIE fighter is:
- Generic description (text);
- Appearances of the TIE fighter in the Star Wars movies (internal links with optimized anchor text);
- Affiliations (internal links with optimized anchor text);
- Dimensions (text);
- Videos;
- Photo gallery;
- Soundboard (famous quotes by characters. In this case, it would be the classic “zzzzeeewww” sound many of us used as the ring tone on our old Nokias :D);
- Quotes (text);
- History (a substantial article with text, images, and links to other documents);
- Related topics (image plus internal links).
In the case of characters like Darth Vader, the information can be even richer.
The effectiveness of the information architecture of the Star Wars website (plus its authority) is such that its Databank is one of the very few non-Wikidata/Wikipedia sources that Google is using as a Knowledge Graph source.

What tool can we use to semantically optimize the structure of a website?
There are, in fact, several tools we can use to semantically optimize the information architecture of a website.
Knowledge Graph Search API
The first one is the Knowledge Graph Search API, because in using it we can get a ranked list of the entities that match given criteria.
This can help us better define the subjects related to a domain (ontology) and can offer ideas about how to structure a website or any kind of web document.
RelFinder
A second tool we can use is RelFinder, which is one of the very few free tools for entity research.
As you can see in the screencast below, RelFinder is based on Wikipedia. Its use is quite simple:
- Choose your main entity (eg: Star Wars);
- Choose the entity you want to see connections with (eg: Star Wars Episode IV: A New Hope);
- Click “Find Relations.”
RelFinder will detect entities related to both (e.g.: George Lucas or Marcia Lucas), their disambiguating properties (e.g.: George Lucas as director, producer, and writer) and factual ones (e.g.: lightsabers as an entity related to Star Wars and first seen in Episode IV).
RelFinder is very useful if we must do entity research on a small scale, such as when preparing a content piece or a small website.
However, if we need to do entity research on a bigger scale, it’s much better to rely on the following tools:
AlchemyAPI and other tools
AlchemyAPI, which was acquired by IBM last year, uses machine and deep learning in order to do natural language processing, semantic text analysis, and computer vision.

AlchemyAPI, which offers a 30-day trial API Key, is based on the Watson technology; it allows us to extract a huge amount of information from text, with concepts, entities, keywords, and taxonomy offered by default.
Resources about AlchemyAPI
Others tools that allow us to do entity extraction and semantic analysis on a big scale are:
Lexical semantics
As said before, lexical semantics is that branch of semantics that studies the meaning of words and their relations.
In the context of semantic search, this area is usually defined as keyword and topical research.
Here on Moz you can find several Whiteboard Friday videos on this topic:
How do we conduct semantically focused keyword and topical research?
Despite its recent update, Keyword Planner still can be useful for performing semantically focused keyword and topical research.
In fact, that update could even be deemed as a logical choice, from a semantic search point of view.
Terms like “PPC” and “pay-per-click” are synonyms, and even though each one surely has a different search volume, it’s evident how Google presents two very similar SERPs if we search for one or the other, especially if our search history already exhibits a pattern of searches related to SEM.
Yet this dimming of keyword data is less helpful for SEOs in that it makes for harder forecasting and prioritization of which keywords to target. This is especially true when we search for head terms, because it exacerbates a problem that Keyword Planner had: combining stemmed keywords that — albeit having “our keyword” as a base — have nothing in common because they mean completely different things and target very different topics.
However (and this is a pro tip), there is a way to discover the most useful keyword, even when they all have the same search volume: how much advertisers bids for it. Trust the market ;-).
(If you want to learn more about the recent changes to Keyword Planner, go read this post by Bill Slawski.)
Keyword Planner for semantic search
Let’s say we want to create a site about Star Wars lightsabers (yes, I am a Star Wars geek).
What we could do is this:

- Open Keyword Planner / Find new Keywords and get (AH!) search volume data;
- Describe our product or service (“News” in the snapshot above);
- Use the Wikipedia page about lightsabers as a landing page (if your site were Spanish, the Wikipedia should be the Spanish one);
- Indicate our product category (Movies & Films above);
- Define the target and eventually indicate negative keywords;
- Click on “Get Ideas.”
Google will offer us these Ad Groups as results:
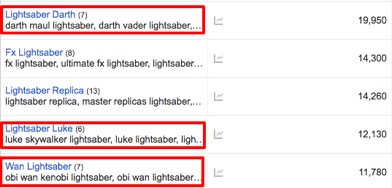
Click to open a bigger version in a new tab
The Ad Groups are a collection of semantically related keywords. They’re very useful for:
- Individuating topics;
- Creating a dictionary of keywords that can be given to writers for text, which will be both natural and semantically consistent.
Remember, then, that Keyword Planner allows us to do other kinds of analysis too, such as breaking down how the discovered keywords/Ad Groups are used by device or by location. This information is useful for understanding the context of our audience.
If you have one or a few entities for which you want to discover topics and grouped keywords, working directly in Keyword Planner and exporting everything to Google Sheets or an Excel file can be enough.
However, when you have tens or hundreds of entities to analyze, it’s much better to use the Adwords API or a tool like SEO Powersuite, which allows you to do keyword research following the method I described above.
Google Suggest, Related Searches, and Moz Keyword Explorer
Alongside with using Keyword Planner, we can use Google Suggest and Related Searches. Not for simply individuating topics that people search and then writing an instant blog post or a landing page about them, but for reaffirming and perfecting our site’s architecture.
Continuing with the example of a site or section specializing in lightsabers, if we look at Google Suggest we can see how “lightsaber replica” is one of the suggestions.

Moreover, amongst the Related Searches for “lightsaber,” we see “lightsaber replica” again, which is a clear signal of its relevance to “lightsaber.”
Finally, we can click on and discover “lightsaber replica”-related searches, thus creating what I define as the “search landscape” about a topic.

The model above is not scalable if we have many entities to analyze. In that case, a tool like Moz Keyword Explorer can be helpful thanks to the options it offers, as you can see in the snapshot below:
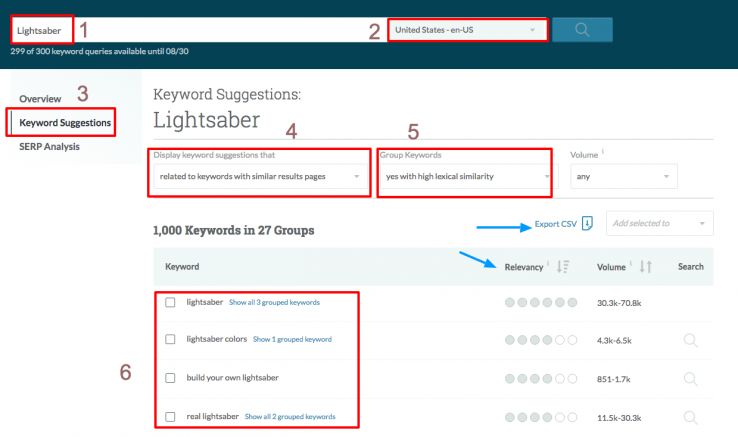
Click to open a bigger version in a new tab
Other keywords and topical research sources
Recently, Powerreviews.com presented survey results that state how Internet users tend to prefer Amazon over Google for searching information about a product (38% vs 35%).
So, why not use Amazon for doing keyword and topical research, especially if we are doing it for ecommerce websites or for the MOFU and BOFU phases of our customers’ journey?
We can use the Amazon Suggest:

Or we can use a free tool like the Amazon Keyword Tool by SISTRIX.
The Suggest function, though, is present in (almost) every website that has a search box (your own site, even, if you have it well-implemented!).
This means that if we’re searching for more mainstream and top-of-the-funnel topics, we can use the suggestions of social networks like Pinterest (i.e.: explore the voluptous universe of the “lightsaber cakes” and related topics):

Pinterest, then, is a real topical research goldmine thanks to its tagging system:

On-page
Once we’ve defined the architecture, the topics, and prepared our keyword dictionaries, we can finally work on the on-page facet of our work.
The details of on-page SEO are another post for another time, so I’ll simply recommend you read this evergreen post by Cyrus Shepard.
The best way to grade the semantic search optimization of a written textis to use TF-IDF analysis, offered by sites like OnPage.org (which offers also a clear guide about the advantages and disadvantages of TF-IDF analyisis).
Remember that TF-IDF can also be used for doing competitive semantic search analysis and to discover the keyword dictionaries used by our competitors.
User behavior / Semiotics and context

In the beginning of this post, we saw how Google is heavily investing in better understanding the meaning of the documents it crawls, so to better answer the queries users perform.
Semantics (and semantic search) is only one of the pillars on which Google is basing this tremendous effort.
The other pillar consists of understanding user search behaviors and the context of the users performing a search.
User search behavior
Recently, Larry Kim shared two posts based on experiments he did, demonstrating his theory about how RankBrain is about factors like CTR and dwell time.
While these posts are super actionable, present interesting information with original data, and confirm other tests conducted in the past, these so-called user signals (CTR and dwell time) may not be directly related to RankBrain but, instead, to user search behaviors and personalized search.
Be aware, however, that my statement here above should be taken as a personal theory, because Google itself doesn’t really know how RankBrain works.
AJ Kohn, Danny Sullivan, and David Harry wrote additional interesting posts about RankBrain, if you want to dig into it (for the record, I wrote about it too here on Moz).
Even if RankBrain may be included in the semantic search landscape due to its use of Word2Vec technology, I find it better to concentrate on how Google may use user search behaviors to better understand the relevance of the parsed and indexed documents.
Click-through rate
Since Rand Fishkin presented his theory — backed up with tests — that Google may use CTR as a ranking factor more than two years ago, a lot has been written about the importance of click-through rate.

Common sense suggests that if people click more often on one search snippet than another that perhaps ranks in a higher position, then Google should take that users’ signal into consideration, and eventually lift the ranking of the page that consistently receives higher CTR.
Common sense, though, is not so easy to apply when it comes to search engines, and repeatedly Googlers have declared that they do not use CTR as a ranking factor (see here and here).
And although Google has long since developed a click fraud detection system for Adwords, it’s still not clear if it would be able to scale it for organic search.
On the other hand — let me be a little bit conspiranoiac — if CTR is not important at all, then why Google has changed the pixels of the title tag and meta description? Just for “better design?”
But as Eric Enge wrote in this post, one of the few things we know is that Google filed a patent (Modifying search result ranking based on a temporal element of user feedback, May 2015) about CTR. It’s surely using CTR in testing environments to better calculate the value and grade of other rankings factors and — this is more speculative — it may give a stronger importance to click-through rate in those subsets of keywords that clearly express a QDF (Query Deserves Freshness) need.
What’s less discussed is the importance CTR has in personalized search, as we know that Google tends to paint a custom SERP for each of us depending on both our search history and our personal click-through rate history. They’re key in helping Google determine which SERPs will be the most useful for us.
For instance:
- If we search something for the first time, and
- for that search we have no search history (or not enough to trigger personalized results), and
- the search presents ambiguous entities (i.e.: “Amber“),
- then it’s only thanks to our personal CTR/search history that Google will determine which search results related to a given entity to show or not (amber the stone or Amber Rose or Amber Alerts…).
Finally, even if Google does not use CTR as a ranking factor, this doesn’t mean it’s not an important metric and signal for SEOs. We have years of experience and hundreds of tests proving how important is to optimize our search snippets (and now Rich Cards) with the appropriate use of structured data in order to earn more organic traffic, even if we rank worst than our competitors.
Watch time
Having good CTR metrics is totally useless if the pages our visitors land on don’t fulfill the expectation the search snippet created.
This is similar to the difference between a clickbait and a persuasive headline. The first will probably cause a click back to the search results page and the second, instead, will trap and engage the visitors.
The ability of a site to retain its users is what we usually call dwell time, but that Google defines as watch time in this patent: Watch Time-Based Ranking (March 2013).
This patent is usually cited in relation to video because the patent itself uses video as content example, but Google doesn’t restrict its definition to videos alone:
In general, “watch time” refers to the total time that a user spends watching a video. However, watch times can also be calculated for and used to rank other types of content based on an amount of time a user spends watching the content.

Watch time is indeed a more useful user signal than CTR for understanding the quality of a web document and its content.
Are you skeptical and don’t trust me? Trust Facebook, then, because it also uses watch time in its news feed algorithm:
We’re learning that the time people choose to spend reading or watching content they clicked on from News Feed is an important signal that the story was interesting to them.
We are adding another factor to News Feed ranking so that we will now predict how long you spend looking at an article in the Facebook mobile browser or an Instant Article after you have clicked through from News Feed. This update to ranking will take into account how likely you are to click on an article and then spend time reading it. We will not be counting loading time towards this — we will be taking into account time spent reading and watching once the content has fully loaded. We will also be looking at the time spent within a threshold so as not to accidentally treat longer articles preferentially.With this change, we can better understand which articles might be interesting to you based on how long you and others read them, so you’ll be more likely to see stories you’re interested in reading.
Context and the importance of personalized search
I usually joke and say that the biggest mistake a gang of bank robbers could do is bring along their smartphones. It’d be quite easy to do PreCrime investigations simply by checking their activity board, which includes their location history on Google Maps.

A conference day in Adelaide.
In order to fulfill its mission of offering the best answers to its users, Google must not only understand the web documents it crawls so to index them properly, and not only improve its own ranking factors (taking into consideration the signals users give during their search sessions), but it also needs to understand the context in which users performs a search.
Here’s what Google knows about us:
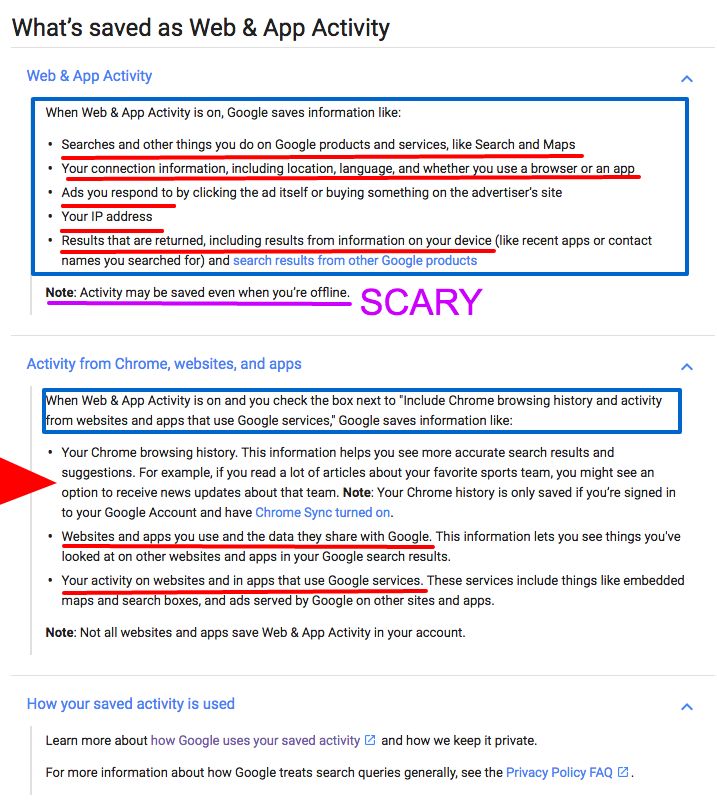
It’s because of this compelling need to understand our context that Google hired the entire Behav.io team back in 2013.
Behav.io, if you don’t know already, was a company that developed an alpha test software based on its open source framework Funf (still alive), the purpose of which was to record and analyze the data that smartphones keep track of: location, speed, nearby devices and networks, phone activity, noise levels, et al.
All this information is required in order to better understand the implicit aspects of a query, especially if done from a smartphone and/or via voice search, and to better process what Tom Anthony and Will Critchlow define as compound queries.
However, personalized search is also determined by (again) entity search, specifically by search entities.
The relation between search entities creates a “probability score,” which may determine if a web document is shown in a determined SERP or not.

For instance, let’s say that someone performs a search about a topic (e.g.: Wookies) for which she never clicked on a search snippet of our site, but on another that had content about that same topic (e.g.: Wookieepedia) and which linked to the page about it on our site (e.g.: “How to distinguish one wookiee from another?”).
Those links — specifically their anchor texts — would help our site and page to earn a higher probability score than a competitor site that isn’t linked to by those sites present in the user’s search history.
This means that our page will have a better probability of appearing in that user’s personalized SERP than our competitors’.
You’re probably asking: what’s the actionable point of this patent?
Link building/earning is not dead at all, because it’s relevant not only to the Link Graph, but also to entity search. In other words, link building is semantic search, too.
The importance of branding and offline marketing for SEO
One of classic complaints SEOs have about Google is how it favors brands.
The real question, though, should be this: “Why aren’t you working to become a brand?”
Be aware! I am not talking about “vision,” “mission,” and “values” here — I’m talking about plain and simple semantics.
All throughout this post I spoke of entities (named and search ones), cited Word2Vec (vectors are “vast amounts of written language embedded into mathematical entities”), talked about lexical semantics, meaning, ontology, personalized search, and implied topics like co-occurrences and knowledge base.
Branding has a lot to do with all of these things.
I’ll try to explain it with a very personal example.
Last May in Valencia I debuted as conference organizer with The Inbounder.
One of the problems I faced when promoting the event was that “inbounder,” which I thought was a cool name for an event targeting inbound marketers, is also a basketball term.
The problem was obvious: how do I make Google understand that The Inbounder was not about basketball, but digital marketing?
The strategy we followed from the very beginning was to work on the branding of the event (I explain more about The Inbounder story here on Inbound.org).
We did this:
- We created small local events, so as to
- develop presence in local newspapers online and offline, a tactic that also obliged marketers to search on Google about the event using branded keywords (e.g.: “The Inbounder conference,” “The Inbounder Inbound Marketing Conference,” etc…), and
- click on our search results snippets, hence activating personalized search
- We worked with influencers (the speakers themselves) to trigger branded searches and direct traffic (remember: Chrome stores every URL we visit);
- We did outreach and published guest posts about the event on sites visited by our audience (and recorded in its search history).
As a result, right now The Inbounder occupies all the first page of Google for its brand name and, more importantly in semantics terms, Google presents The Inbounder events as suggested and related searches. It associates it with all the searches I could ever want:
 Another example is Trivago and its global TV advertising campaigns:
Another example is Trivago and its global TV advertising campaigns:

Trivago was very smart in constantly showing “Trivago” and “hotel” in the same phrase, even making their motto “Hotel? Trivago.”
This is a simple psychological trick for creating word associations.
As a result, people searched on Google for “hotel Trivago” (or “Trivago hotel”), especially just after the ads were broadcasted:
 One of the results is that now, Google suggests “hotel Trivago” when we start typing “hotel” and, as in the case of The Inbounder, it presents “hotel Trivago” as a related search:
One of the results is that now, Google suggests “hotel Trivago” when we start typing “hotel” and, as in the case of The Inbounder, it presents “hotel Trivago” as a related search:

Wake up SEOs, the new new Google is here
Yes, it is. And it’s all about better understanding web documents and queries in order to provide the best answers to its users (and make money in the meantime).
To achieve this objective, ideally becoming the long-desired “Star Trek computer,” Google is investing money, people, and efforts into machine/deep learning, neural networks, semantics, search behavior, context analysis, and personalized search.
Remember, SEO is no longer just about “200 ranking factors.” SEO is about making our websites become the sources Google cannot help but use for answering queries.
This is exactly why semantic search is of utmost importance and not just something worth the attention of a few geeks passionate about linguistics, computer science, and patents.
Work on parsing and indexing optimization now, seriously implement semantic search in your SEO strategy, take advantage of the opportunities personalized search offers you, and always put users at the center of everything you do.
In doing so you’ll build a solid foundation for your success in the years to come, both via classic search and with Google Assistant/Now.